Messaging
Pulsar is built on the publish-subscribe pattern (often abbreviated to pub-sub). In this pattern, producers publish messages to topics. Consumers subscribe to those topics, process incoming messages, and send an acknowledgement when processing is complete.
When a subscription is created, Pulsar retains all messages, even if the consumer is disconnected. Retained messages are discarded only when a consumer acknowledges that those messages are processed successfully.
Messages
Messages are the basic "unit" of Pulsar. The following table lists the components of messages.
| Component | Description |
|---|---|
| Value / data payload | The data carried by the message. All Pulsar messages contain raw bytes, although message data can also conform to data schemas. |
| Key | Messages are optionally tagged with keys, which is useful for things like topic compaction. |
| Properties | An optional key/value map of user-defined properties. |
| Producer name | The name of the producer who produces the message. If you do not specify a producer name, the default name is used. |
| Sequence ID | Each Pulsar message belongs to an ordered sequence on its topic. The sequence ID of the message is its order in that sequence. |
| Publish time | The timestamp of when the message is published. The timestamp is automatically applied by the producer. |
| Event time | An optional timestamp attached to a message by applications. For example, applications attach a timestamp on when the message is processed. If nothing is set to event time, the value is 0. |
| TypedMessageBuilder | It is used to construct a message. You can set message properties such as the message key, message value with TypedMessageBuilder. When you set TypedMessageBuilder, set the key as a string. If you set the key as other types, for example, an AVRO object, the key is sent as bytes, and it is difficult to get the AVRO object back on the consumer. |
For more information on Pulsar message contents, see Pulsar binary protocol.
Producers
A producer is a process that attaches to a topic and publishes messages to a Pulsar broker. The Pulsar broker process the messages.
Send modes
Producers send messages to brokers synchronously (sync) or asynchronously (async).
| Mode | Description |
|---|---|
| Sync send | The producer waits for an acknowledgement from the broker after sending every message. If the acknowledgment is not received, the producer treats the sending operation as a failure. |
| Async send | The producer puts a message in a blocking queue and returns immediately. The client library sends the message to the broker in the background. If the queue is full (you can configure the maximum size), the producer is blocked or fails immediately when calling the API, depending on arguments passed to the producer. |
Compression
You can compress messages published by producers during transportation. Pulsar currently supports the following types of compression:
Batching
When batching is enabled, the producer accumulates and sends a batch of messages in a single request. The batch size is defined by the maximum number of messages and the maximum publish latency. Therefore, the backlog size represents the total number of batches instead of the total number of messages.
In Pulsar, batches are tracked and stored as single units rather than as individual messages. Consumer unbundles a batch into individual messages. However, scheduled messages (configured through the deliverAt or the deliverAfter parameter) are always sent as individual messages even batching is enabled.
In general, a batch is acknowledged when all of its messages are acknowledged by a consumer. It means unexpected failures, negative acknowledgements, or acknowledgement timeouts can result in redelivery of all messages in a batch, even if some of the messages are acknowledged.
To avoid redelivering acknowledged messages in a batch to the consumer, Pulsar introduces batch index acknowledgement since Pulsar 2.6.0. When batch index acknowledgement is enabled, the consumer filters out the batch index that has been acknowledged and sends the batch index acknowledgement request to the broker. The broker maintains the batch index acknowledgement status and tracks the acknowledgement status of each batch index to avoid dispatching acknowledged messages to the consumer. When all indexes of the batch message are acknowledged, the batch message is deleted.
By default, batch index acknowledgement is disabled (acknowledgmentAtBatchIndexLevelEnabled=false). You can enable batch index acknowledgement by setting the acknowledgmentAtBatchIndexLevelEnabled parameter to true at the broker side. Enabling batch index acknowledgement results in more memory overheads.
Chunking
When you enable chunking, read the following instructions.
- Batching and chunking cannot be enabled simultaneously. To enable chunking, you must disable batching in advance.
- Chunking is only supported for persisted topics.
- Chunking is only supported for the exclusive and failover subscription types.
When chunking is enabled (chunkingEnabled=true), if the message size is greater than the allowed maximum publish-payload size, the producer splits the original message into chunked messages and publishes them with chunked metadata to the broker separately and in order. At the broker side, the chunked messages are stored in the managed-ledger in the same way as that of ordinary messages. The only difference is that the consumer needs to buffer the chunked messages and combines them into the real message when all chunked messages have been collected. The chunked messages in the managed-ledger can be interwoven with ordinary messages. If producer fails to publish all the chunks of a message, the consumer can expire incomplete chunks if consumer fail to receive all chunks in expire time. By default, the expire time is set to one minute.
The consumer consumes the chunked messages and buffers them until the consumer receives all the chunks of a message. And then the consumer stitches chunked messages together and places them into the receiver-queue. Clients consume messages from the receiver-queue. Once the consumer consumes the entire large message and acknowledges it, the consumer internally sends acknowledgement of all the chunk messages associated to that large message. You can set the maxPendingChuckedMessage parameter on the consumer. When the threshold is reached, the consumer drops the unchunked messages by silently acknowledging them or asking the broker to redeliver them later by marking them unacknowledged.
The broker does not require any changes to support chunking for non-shared subscription. The broker only uses chuckedMessageRate to record chunked message rate on the topic.
Handle chunked messages with one producer and one ordered consumer
As shown in the following figure, when a topic has one producer which publishes large message payload in chunked messages along with regular non-chunked messages. The producer publishes message M1 in three chunks M1-C1, M1-C2 and M1-C3. The broker stores all the three chunked messages in the managed-ledger and dispatches to the ordered (exclusive/failover) consumer in the same order. The consumer buffers all the chunked messages in memory until it receives all the chunked messages, combines them into one message and then hands over the original message M1 to the client.
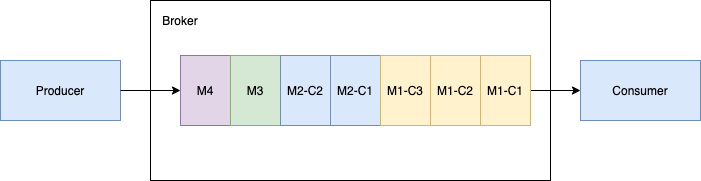
Handle chunked messages with multiple producers and one ordered consumer
When multiple publishers publish chunked messages into a single topic, the broker stores all the chunked messages coming from different publishers in the same managed-ledger. As shown below, Producer 1 publishes message M1 in three chunks M1-C1, M1-C2 and M1-C3. Producer 2 publishes message M2 in three chunks M2-C1, M2-C2 and M2-C3. All chunked messages of the specific message are still in order but might not be consecutive in the managed-ledger. This brings some memory pressure to the consumer because the consumer keeps separate buffer for each large message to aggregate all chunks of the large message and combine them into one message.
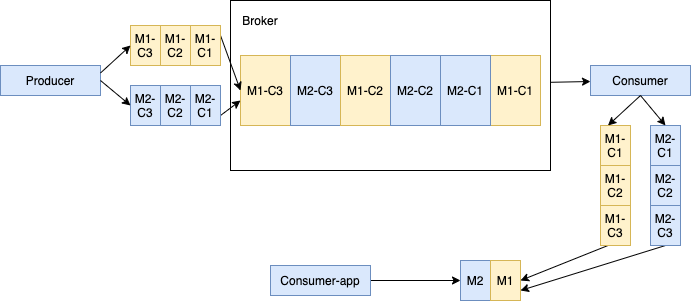
Consumers
A consumer is a process that attaches to a topic via a subscription and then receives messages.
A consumer sends a flow permit request to a broker to get messages. There is a queue at the consumer side to receive messages pushed from the broker. You can configure the queue size with the receiverQueueSize parameter. The default size is 1000). Each time consumer.receive() is called, a message is dequeued from the buffer.
Receive modes
Messages are received from brokers either synchronously (sync) or asynchronously (async).
| Mode | Description |
|---|---|
| Sync receive | A sync receive is blocked until a message is available. |
| Async receive | An async receive returns immediately with a future value—for example, a CompletableFuture in Java—that completes once a new message is available. |
Listeners
Client libraries provide listener implementation for consumers. For example, the Java client provides a MesssageListener interface. In this interface, the received method is called whenever a new message is received.
Acknowledgement
When a consumer consumes a message successfully, the consumer sends an acknowledgement request to the broker. This message is permanently stored, and then deleted only after all the subscriptions have acknowledged it. If you want to store the message that has been acknowledged by a consumer, you need to configure the message retention policy.
For a batch message, if batch index acknowledgement is enabled, the broker maintains the batch index acknowledgement status and tracks the acknowledgement status of each batch index to avoid dispatching acknowledged messages to the consumer. When all indexes of the batch message are acknowledged, the batch message is deleted. For details about the batch index acknowledgement, see batching.
Messages can be acknowledged in the following two ways:
- Messages are acknowledged individually. With individual acknowledgement, the consumer needs to acknowledge each message and sends an acknowledgement request to the broker.
- Messages are acknowledged cumulatively. With cumulative acknowledgement, the consumer only needs to acknowledge the last message it received. All messages in the stream up to (and including) the provided message are not re-delivered to that consumer.
Cumulative acknowledgement cannot be used in Shared subscription type, because this subscription type involves multiple consumers which have access to the same subscription. In Shared subscription type, messages are acknowledged individually.
Negative acknowledgement
When a consumer does not consume a message successfully at a time, and wants to consume the message again, the consumer sends a negative acknowledgement to the broker, and then the broker redelivers the message.
Messages are negatively acknowledged either individually or cumulatively, depending on the consumption subscription type.
In the exclusive and failover subscription types, consumers only negatively acknowledge the last message they receive.
In the shared and Key_Shared subscription types, you can negatively acknowledge messages individually.
Be aware that negative acknowledgment on ordered subscription types, such as Exclusive, Failover and Key_Shared, can cause failed messages to arrive consumers out of the original order.
If batching is enabled, other messages and the negatively acknowledged messages in the same batch are redelivered to the consumer.
Acknowledgement timeout
If a message is not consumed successfully, and you want to trigger the broker to redeliver the message automatically, you can adopt the unacknowledged message automatic re-delivery mechanism. Client tracks the unacknowledged messages within the entire acktimeout time range, and sends a redeliver unacknowledged messages request to the broker automatically when the acknowledgement timeout is specified.
If batching is enabled, other messages and the unacknowledged messages in the same batch are redelivered to the consumer.
Prefer negative acknowledgements over acknowledgement timeout. Negative acknowledgement controls the re-delivery of individual messages with more precision, and avoids invalid redeliveries when the message processing time exceeds the acknowledgement timeout.
Dead letter topic
Dead letter topic enables you to consume new messages when some messages cannot be consumed successfully by a consumer. In this mechanism, messages that are failed to be consumed are stored in a separate topic, which is called dead letter topic. You can decide how to handle messages in the dead letter topic.
The following example shows how to enable dead letter topic in a Java client using the default dead letter topic:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();
The default dead letter topic uses this format:
<topicname>-<subscriptionname>-DLQ
If you want to specify the name of the dead letter topic, use this Java client example:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.deadLetterTopic("your-topic-name")
.build())
.subscribe();
Dead letter topic depends on message re-delivery. Messages are redelivered either due to acknowledgement timeout or negative acknowledgement. If you are going to use negative acknowledgement on a message, make sure it is negatively acknowledged before the acknowledgement timeout.
Currently, dead letter topic is enabled only in Shared subscription type.
Retry letter topic
For many online business systems, a message is re-consumed due to exception occurs in the business logic processing. To configure the delay time for re-consuming the failed messages, you can configure the producer to send messages to both the business topic and the retry letter topic, and enable automatic retry on the consumer. When automatic retry is enabled on the consumer, a message is stored in the retry letter topic if the messages are not consumed, and therefore the consumer automatically consumes the failed messages from the retry letter topic after a specified delay time.
By default, automatic retry is disabled. You can set enableRetry to true to enable automatic retry on the consumer.
This example shows how to consume messages from a retry letter topic.
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.enableRetry(true)
.receiverQueueSize(100)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.retryLetterTopic("persistent://my-property/my-ns/my-subscription-custom-Retry")
.build())
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.subscribe();
Topics
As in other pub-sub systems, topics in Pulsar are named channels for transmitting messages from producers to consumers. Topic names are URLs that have a well-defined structure:
{persistent|non-persistent}://tenant/namespace/topic
| Topic name component | Description |
|---|---|
persistent / non-persistent | This identifies the type of topic. Pulsar supports two kind of topics: persistent and non-persistent. The default is persistent, so if you do not specify a type, the topic is persistent. With persistent topics, all messages are durably persisted on disks (if the broker is not standalone, messages are durably persisted on multiple disks), whereas data for non-persistent topics is not persisted to storage disks. |
tenant | The topic tenant within the instance. Tenants are essential to multi-tenancy in Pulsar, and spread across clusters. |
namespace | The administrative unit of the topic, which acts as a grouping mechanism for related topics. Most topic configuration is performed at the namespace level. Each tenant has one or multiple namespaces. |
topic | The final part of the name. Topic names have no special meaning in a Pulsar instance. |
No need to explicitly create new topics You do not need to explicitly create topics in Pulsar. If a client attempts to write or receive messages to/from a topic that does not yet exist, Pulsar creates that topic under the namespace provided in the topic name automatically. If no tenant or namespace is specified when a client creates a topic, the topic is created in the default tenant and namespace. You can also create a topic in a specified tenant and namespace, such as
persistent://my-tenant/my-namespace/my-topic.persistent://my-tenant/my-namespace/my-topicmeans themy-topictopic is created in themy-namespacenamespace of themy-tenanttenant.
Namespaces
A namespace is a logical nomenclature within a tenant. A tenant creates multiple namespaces via the admin API. For instance, a tenant with different applications can create a separate namespace for each application. A namespace allows the application to create and manage a hierarchy of topics. The topic my-tenant/app1 is a namespace for the application app1 for my-tenant. You can create any number of topics under the namespace.
Subscriptions
A subscription is a named configuration rule that determines how messages are delivered to consumers. Four subscription types are available in Pulsar: exclusive, shared, failover, and key_shared. These types are illustrated in the figure below.
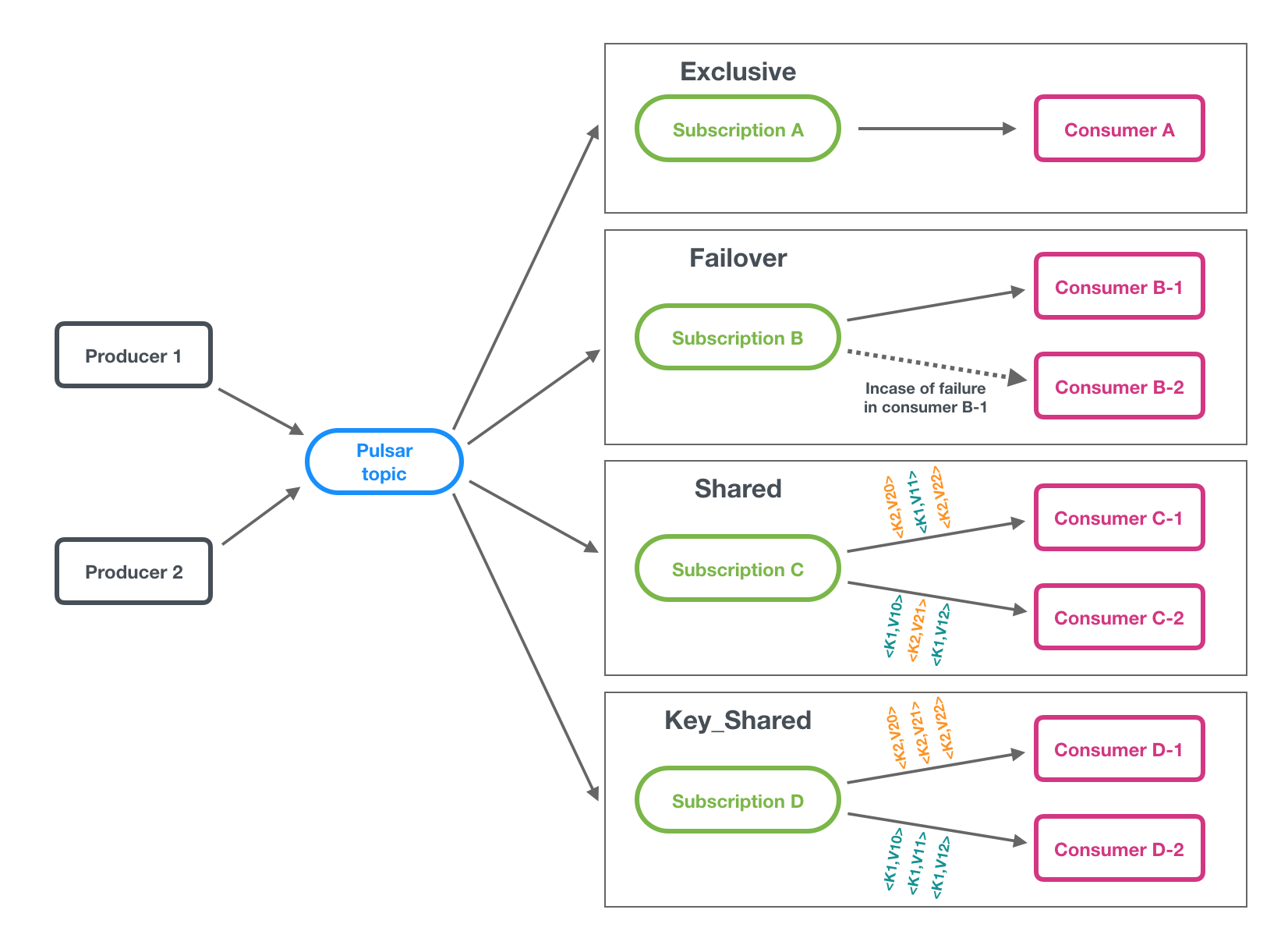
Pub-Sub or Queuing In Pulsar, you can use different subscriptions flexibly.
- If you want to achieve traditional "fan-out pub-sub messaging" among consumers, specify a unique subscription name for each consumer. It is exclusive subscription type.
- If you want to achieve "message queuing" among consumers, share the same subscription name among multiple consumers(shared, failover, key_shared).
- If you want to achieve both effects simultaneously, combine exclusive subscription type with other subscription types for consumers.
Subscription types
When a subscription has no consumers, its subscription type is undefined. The type of a subscription is defined when a consumer connects to it, and the type can be changed by restarting all consumers with a different configuration.
Exclusive
In exclusive type, only a single consumer is allowed to attach to the subscription. If multiple consumers subscribe to a topic using the same subscription, an error occurs.
In the diagram below, only Consumer A-0 is allowed to consume messages.
Exclusive is the default subscription type.
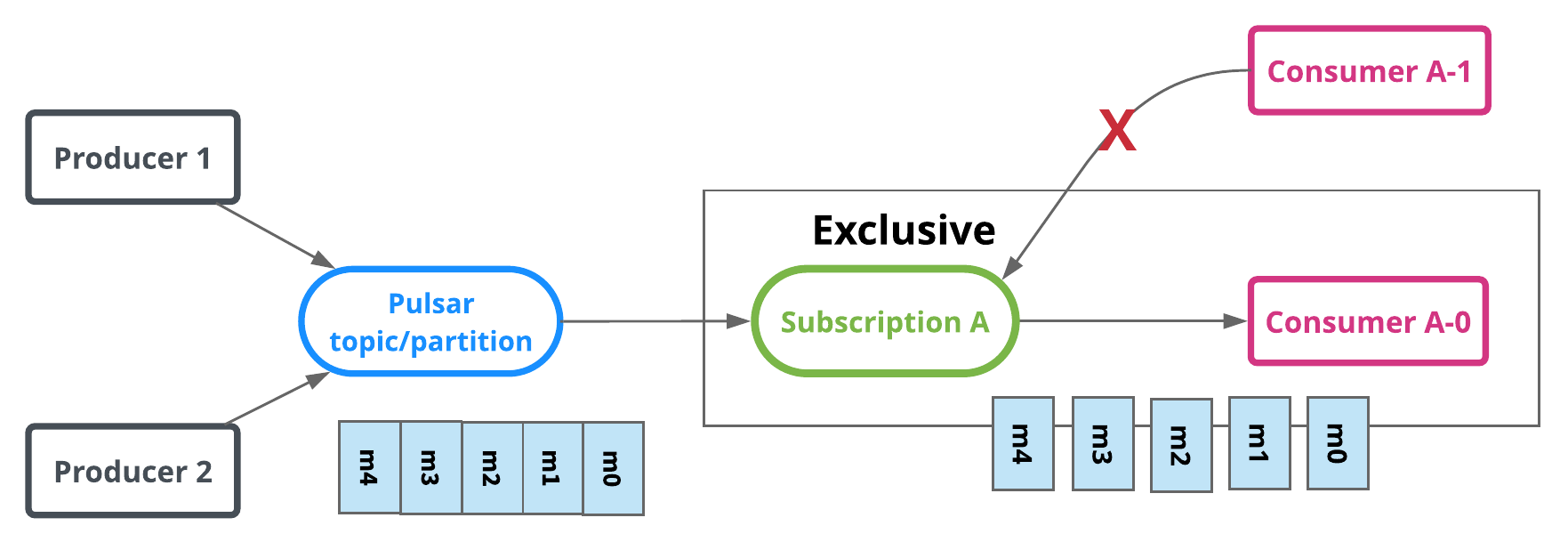
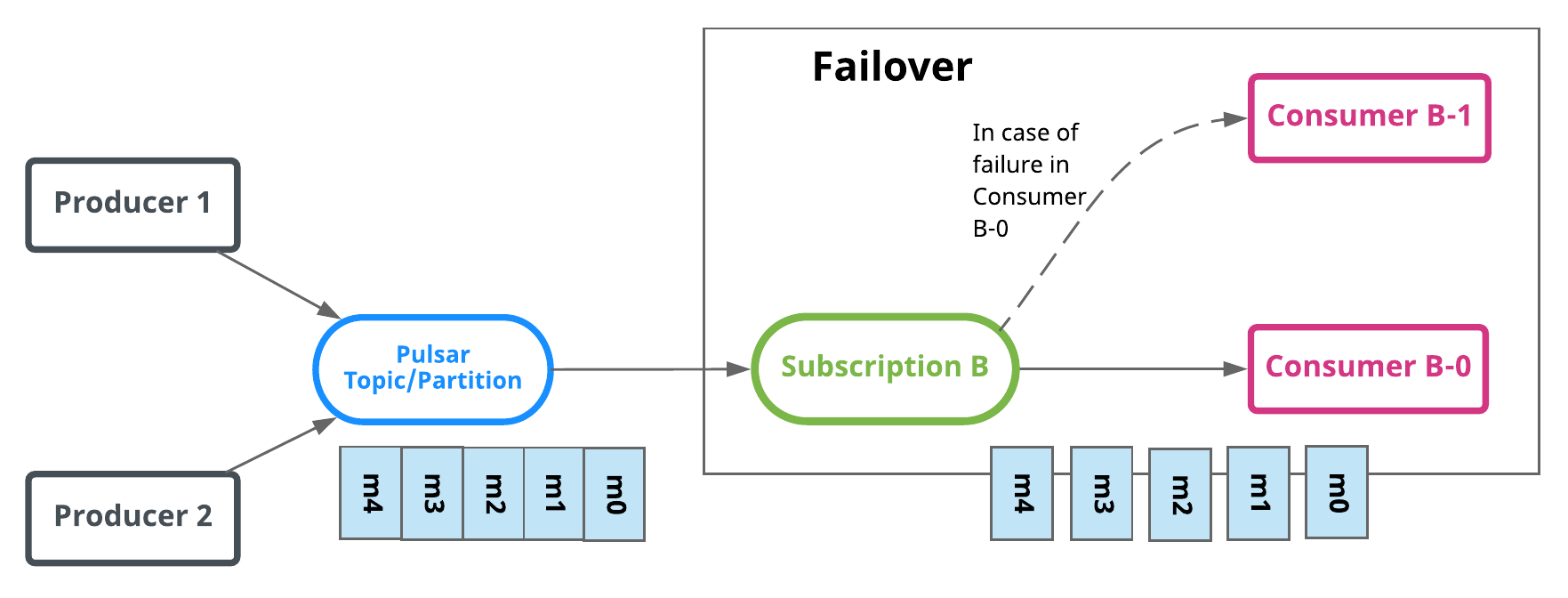
Failover
In Failover type, multiple consumers can attach to the same subscription. A master consumer is picked for non-partitioned topic or each partition of partitioned topic and receives messages. When the master consumer disconnects, all (non-acknowledged and subsequent) messages are delivered to the next consumer in line.
For partitioned topics, broker will sort consumers by priority level and lexicographical order of consumer name. Then broker will try to evenly assigns topics to consumers with the highest priority level.
For non-partitioned topic, broker will pick consumer in the order they subscribe to the non partitioned topic.
In the diagram below, Consumer-B-0 is the master consumer while Consumer-B-1 would be the next consumer in line to receive messages if Consumer-B-0 is disconnected.
Shared
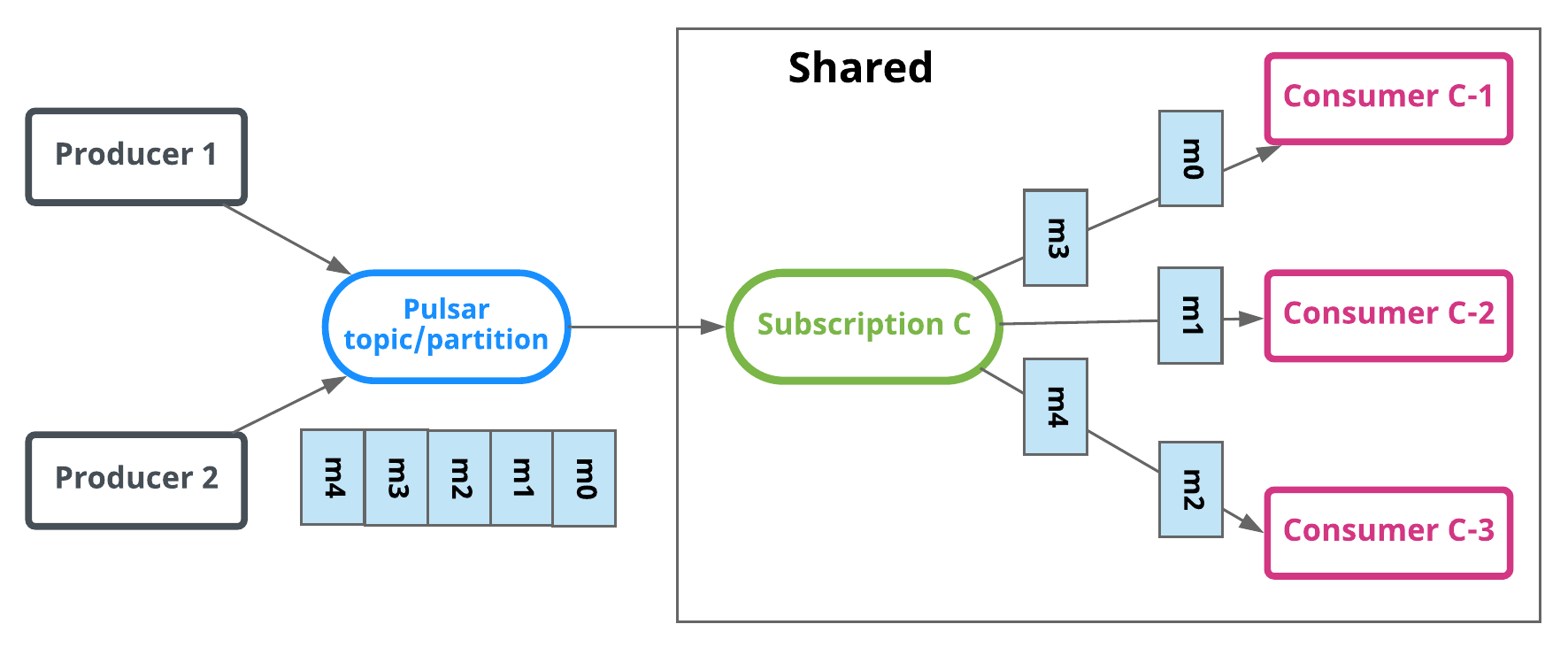
In shared or round robin mode, multiple consumers can attach to the same subscription. Messages are delivered in a round robin distribution across consumers, and any given message is delivered to only one consumer. When a consumer disconnects, all the messages that were sent to it and not acknowledged will be rescheduled for sending to the remaining consumers.
In the diagram below, Consumer-C-1 and Consumer-C-2 are able to subscribe to the topic, but Consumer-C-3 and others could as well.
Limitations of shared type When using Shared type, be aware that:
- Message ordering is not guaranteed.
- You cannot use cumulative acknowledgment with Shared type.
Key_Shared
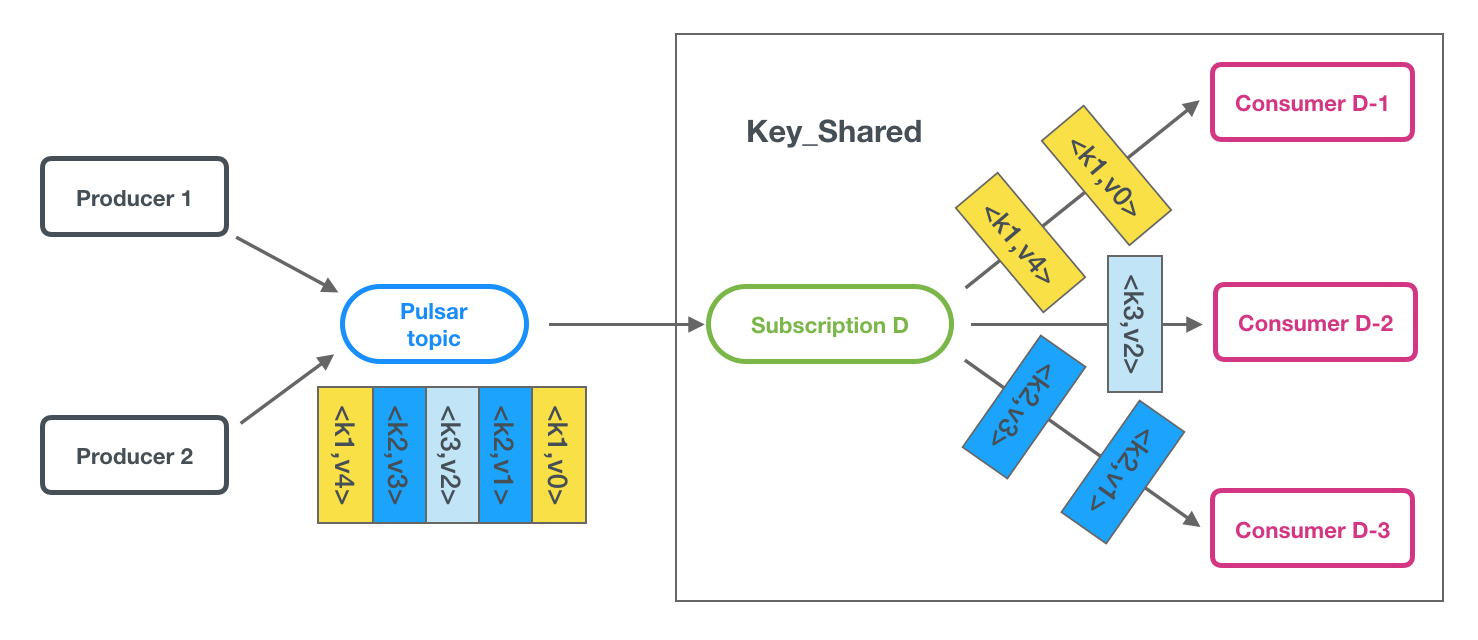
In Key_Shared type, multiple consumers can attach to the same subscription. Messages are delivered in a distribution across consumers and message with same key or same ordering key are delivered to only one consumer. No matter how many times the message is re-delivered, it is delivered to the same consumer. When a consumer connected or disconnected will cause served consumer change for some key of message.
Limitations of Key_Shared type When you use Key_Shared type, be aware that:
- You need to specify a key or orderingKey for messages.
- You cannot use cumulative acknowledgment with Key_Shared type.
- Your producers should disable batching or use a key-based batch builder.
You can disable Key_Shared subscription in the broker.config file.
Subscription modes
What is a subscription mode
The subscription mode indicates the cursor type.
- When a subscription is created, an associated cursor is created to record the last consumed position.
- When a consumer of the subscription restarts, it can continue consuming from the last message it consumes.
| Subscription mode | Description | Note |
|---|---|---|
Durable | The cursor is durable, which retains messages and persists the current position. If a broker restarts from a failure, it can recover the cursor from the persistent storage (BookKeeper), so that messages can continue to be consumed from the last consumed position. | Durable is the default subscription mode. |
NonDurable | The cursor is non-durable. Once a broker stops, the cursor is lost and can never be recovered, so that messages can not continue to be consumed from the last consumed position. | Reader’s subscription mode is NonDurable in nature and it does not prevent data in a topic from being deleted. Reader’s subscription mode can not be changed. |
A subscription can have one or more consumers. When a consumer subscribes to a topic, it must specify the subscription name. A durable subscription and a non-durable subscription can have the same name, they are independent of each other. If a consumer specifies a subscription which does not exist before, the subscription is automatically created.
When to use
By default, messages of a topic without any durable subscriptions are marked as deleted. If you want to prevent the messages being marked as deleted, you can create a durable subscription for this topic. In this case, only acknowledged messages are marked as deleted. For more information, see message retention and expiry.
How to use
After a consumer is created, the default subscription mode of the consumer is Durable. You can change the subscription mode to NonDurable by making changes to the consumer’s configuration.
- Durable
- Non-durable
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("my-topic")
.subscriptionName("my-sub")
.subscriptionMode(SubscriptionMode.Durable)
.subscribe();
Consumer<byte[]> consumer = pulsarClient.newConsumer()
.topic("my-topic")
.subscriptionName("my-sub")
.subscriptionMode(SubscriptionMode.NonDurable)
.subscribe();
For how to create, check, or delete a durable subscription, see manage subscriptions.
Multi-topic subscriptions
When a consumer subscribes to a Pulsar topic, by default it subscribes to one specific topic, such as persistent://public/default/my-topic. As of Pulsar version 1.23.0-incubating, however, Pulsar consumers can simultaneously subscribe to multiple topics. You can define a list of topics in two ways:
- On the basis of a regular expression (regex), for example
persistent://public/default/finance-.* - By explicitly defining a list of topics
When subscribing to multiple topics by regex, all topics must be in the same namespace.
When subscribing to multiple topics, the Pulsar client automatically makes a call to the Pulsar API to discover the topics that match the regex pattern/list, and then subscribe to all of them. If any of the topics do not exist, the consumer auto-subscribes to them once the topics are created.
No ordering guarantees across multiple topics When a producer sends messages to a single topic, all messages are guaranteed to be read from that topic in the same order. However, these guarantees do not hold across multiple topics. So when a producer sends message to multiple topics, the order in which messages are read from those topics is not guaranteed to be the same.
The following are multi-topic subscription examples for Java.
import java.util.regex.Pattern;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.PulsarClient;
PulsarClient pulsarClient = // Instantiate Pulsar client object
// Subscribe to all topics in a namespace
Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default/.*");
Consumer<byte[]> allTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(allTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
// Subscribe to a subsets of topics in a namespace, based on regex
Pattern someTopicsInNamespace = Pattern.compile("persistent://public/default/foo.*");
Consumer<byte[]> someTopicsConsumer = pulsarClient.newConsumer()
.topicsPattern(someTopicsInNamespace)
.subscriptionName("subscription-1")
.subscribe();
For code examples, see Java.
Partitioned topics
Normal topics are served only by a single broker, which limits the maximum throughput of the topic. Partitioned topics are a special type of topic that are handled by multiple brokers, thus allowing for higher throughput.
A partitioned topic is actually implemented as N internal topics, where N is the number of partitions. When publishing messages to a partitioned topic, each message is routed to one of several brokers. The distribution of partitions across brokers is handled automatically by Pulsar.
The diagram below illustrates this:
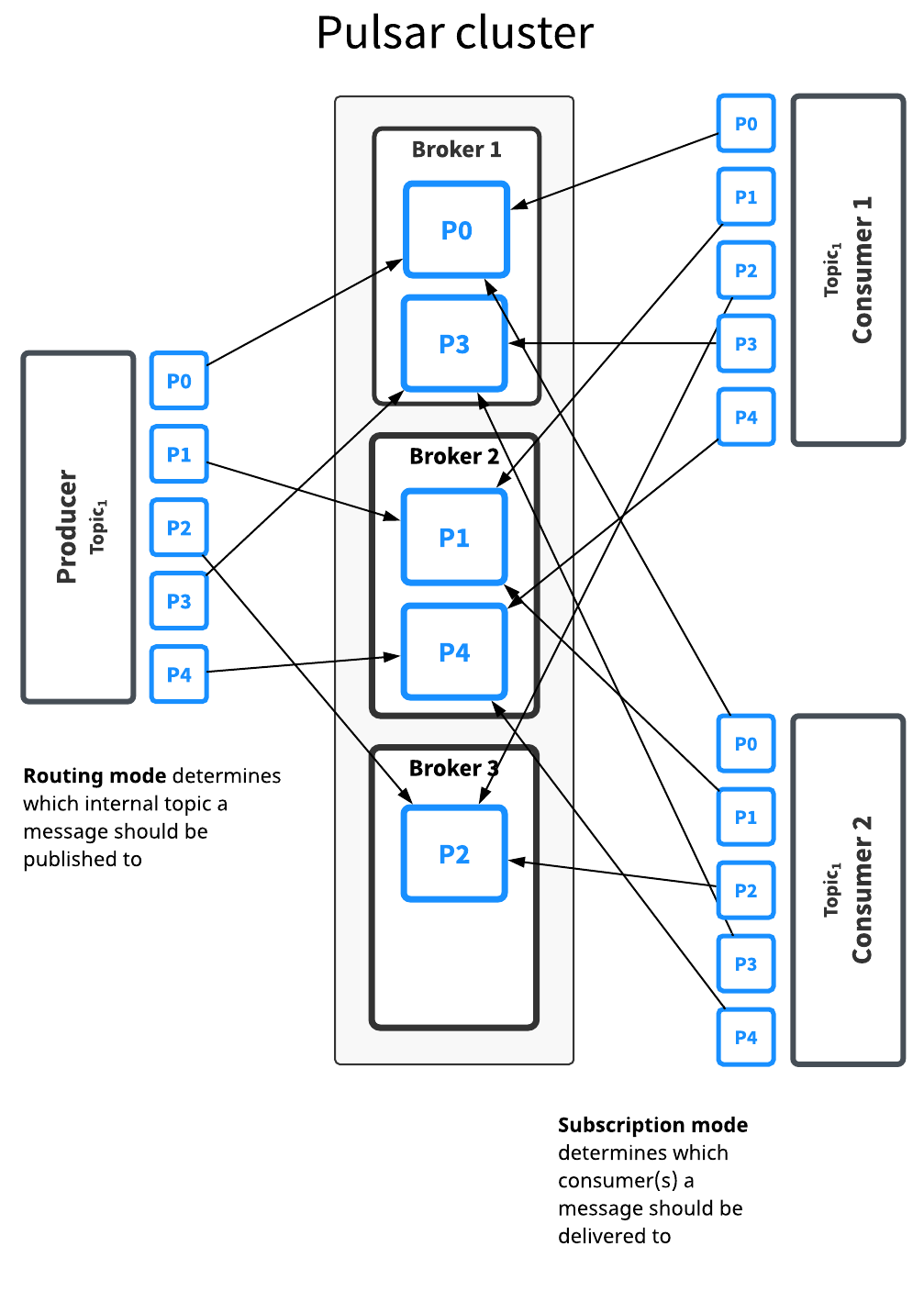
The Topic1 topic has five partitions (P0 through P4) split across three brokers. Because there are more partitions than brokers, two brokers handle two partitions a piece, while the third handles only one (again, Pulsar handles this distribution of partitions automatically).
Messages for this topic are broadcast to two consumers. The routing mode determines each message should be published to which partition, while the subscription type determines which messages go to which consumers.
Decisions about routing and subscription types can be made separately in most cases. In general, throughput concerns should guide partitioning/routing decisions while subscription decisions should be guided by application semantics.
There is no difference between partitioned topics and normal topics in terms of how subscription types work, as partitioning only determines what happens between when a message is published by a producer and processed and acknowledged by a consumer.
Partitioned topics need to be explicitly created via the admin API. The number of partitions can be specified when creating the topic.
Routing modes
When publishing to partitioned topics, you must specify a routing mode. The routing mode determines which partition---that is, which internal topic---each message should be published to.
There are three MessageRoutingMode available:
| Mode | Description |
|---|---|
RoundRobinPartition | If no key is provided, the producer will publish messages across all partitions in round-robin fashion to achieve maximum throughput. Please note that round-robin is not done per individual message but rather it's set to the same boundary of batching delay, to ensure batching is effective. While if a key is specified on the message, the partitioned producer will hash the key and assign message to a particular partition. This is the default mode. |
SinglePartition | If no key is provided, the producer will randomly pick one single partition and publish all the messages into that partition. While if a key is specified on the message, the partitioned producer will hash the key and assign message to a particular partition. |
CustomPartition | Use custom message router implementation that will be called to determine the partition for a particular message. User can create a custom routing mode by using the Java client and implementing the MessageRouter interface. |
Ordering guarantee
The ordering of messages is related to MessageRoutingMode and Message Key. Usually, user would want an ordering of Per-key-partition guarantee.
If there is a key attached to message, the messages will be routed to corresponding partitions based on the hashing scheme specified by HashingScheme in ProducerBuilder, when using either SinglePartition or RoundRobinPartition mode.
| Ordering guarantee | Description | Routing Mode and Key |
|---|---|---|
| Per-key-partition | All the messages with the same key will be in order and be placed in same partition. | Use either SinglePartition or RoundRobinPartition mode, and Key is provided by each message. |
| Per-producer | All the messages from the same producer will be in order. | Use SinglePartition mode, and no Key is provided for each message. |
Hashing scheme
HashingScheme is an enum that represent sets of standard hashing functions available when choosing the partition to use for a particular message.
There are 2 types of standard hashing functions available: JavaStringHash and Murmur3_32Hash.
The default hashing function for producer is JavaStringHash.
Please pay attention that JavaStringHash is not useful when producers can be from different multiple language clients, under this use case, it is recommended to use Murmur3_32Hash.
Non-persistent topics
By default, Pulsar persistently stores all unacknowledged messages on multiple BookKeeper bookies (storage nodes). Data for messages on persistent topics can thus survive broker restarts and subscriber failover.
Pulsar also, however, supports non-persistent topics, which are topics on which messages are never persisted to disk and live only in memory. When using non-persistent delivery, killing a Pulsar broker or disconnecting a subscriber to a topic means that all in-transit messages are lost on that (non-persistent) topic, meaning that clients may see message loss.
Non-persistent topics have names of this form (note the non-persistent in the name):
non-persistent://tenant/namespace/topic
For more info on using non-persistent topics, see the Non-persistent messaging cookbook.
In non-persistent topics, brokers immediately deliver messages to all connected subscribers without persisting them in BookKeeper. If a subscriber is disconnected, the broker will not be able to deliver those in-transit messages, and subscribers will never be able to receive those messages again. Eliminating the persistent storage step makes messaging on non-persistent topics slightly faster than on persistent topics in some cases, but with the caveat that some of the core benefits of Pulsar are lost.
With non-persistent topics, message data lives only in memory. If a message broker fails or message data can otherwise not be retrieved from memory, your message data may be lost. Use non-persistent topics only if you're certain that your use case requires it and can sustain it.
By default, non-persistent topics are enabled on Pulsar brokers. You can disable them in the broker's configuration](reference-configuration.md#broker-enableNonPersistentTopics). You can manage non-persistent topics using the pulsar-admin topics command. For more information, see [pulsar-admin.
Performance
Non-persistent messaging is usually faster than persistent messaging because brokers don't persist messages and immediately send acks back to the producer as soon as that message is delivered to connected brokers. Producers thus see comparatively low publish latency with non-persistent topic.
Client API
Producers and consumers can connect to non-persistent topics in the same way as persistent topics, with the crucial difference that the topic name must start with non-persistent. All three subscription types---exclusive, shared, and failover---are supported for non-persistent topics.
Here's an example Java consumer for a non-persistent topic:
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
String npTopic = "non-persistent://public/default/my-topic";
String subscriptionName = "my-subscription-name";
Consumer<byte[]> consumer = client.newConsumer()
.topic(npTopic)
.subscriptionName(subscriptionName)
.subscribe();
Here's an example Java producer for the same non-persistent topic:
Producer<byte[]> producer = client.newProducer()
.topic(npTopic)
.create();
Message retention and expiry
By default, Pulsar message brokers:
- immediately delete all messages that have been acknowledged by a consumer, and
- persistently store all unacknowledged messages in a message backlog.
Pulsar has two features, however, that enable you to override this default behavior:
- Message retention enables you to store messages that have been acknowledged by a consumer
- Message expiry enables you to set a time to live (TTL) for messages that have not yet been acknowledged
All message retention and expiry is managed at the namespace level. For a how-to, see the Message retention and expiry cookbook.
The diagram below illustrates both concepts:
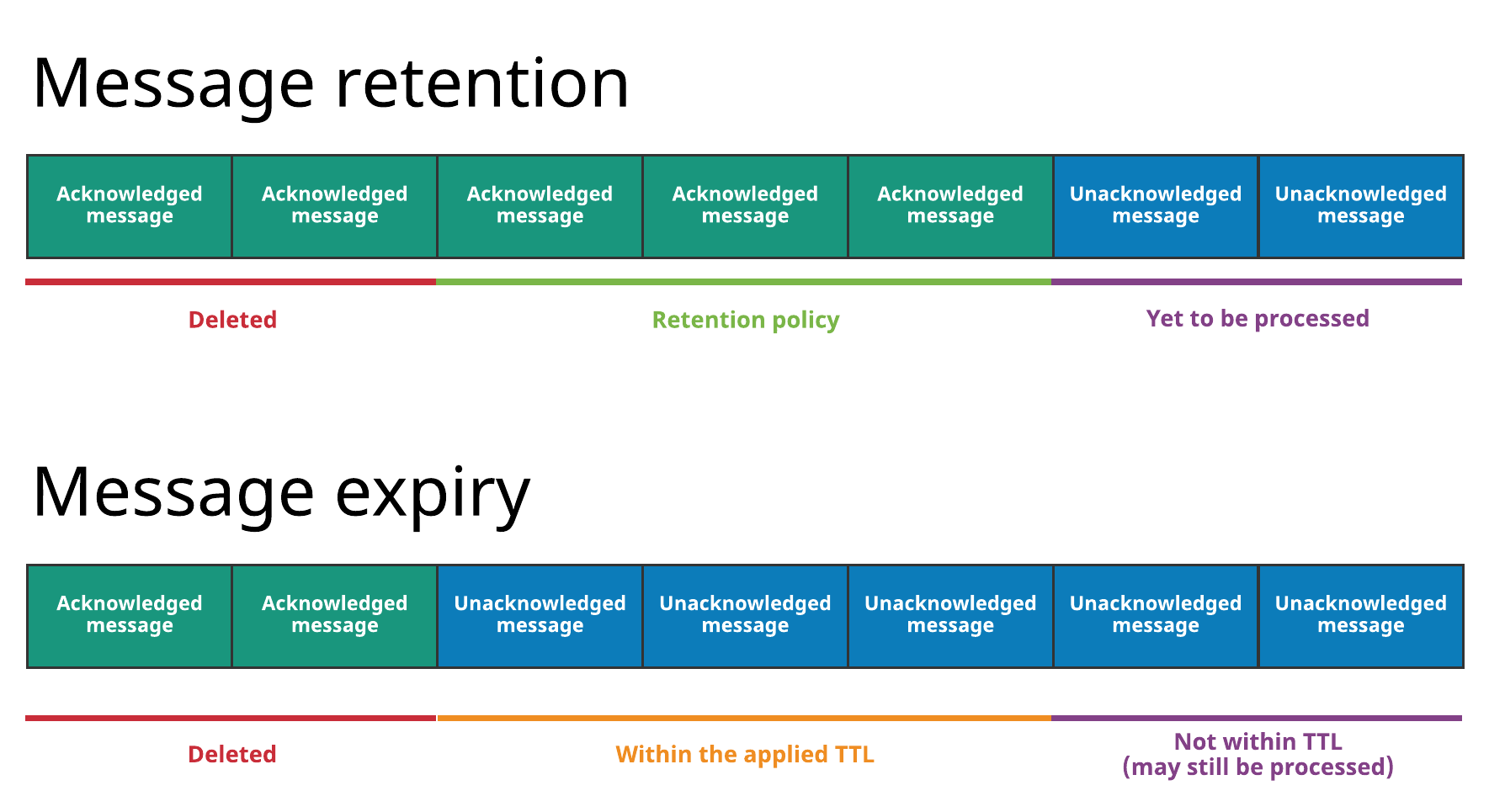
With message retention, shown at the top, a retention policy applied to all topics in a namespace dictates that some messages are durably stored in Pulsar even though they've already been acknowledged. Acknowledged messages that are not covered by the retention policy are deleted. Without a retention policy, all of the acknowledged messages would be deleted.
With message expiry, shown at the bottom, some messages are deleted, even though they haven't been acknowledged, because they've expired according to the TTL applied to the namespace (for example because a TTL of 5 minutes has been applied and the messages haven't been acknowledged but are 10 minutes old).
Message deduplication
Message duplication occurs when a message is persisted by Pulsar more than once. Message deduplication is an optional Pulsar feature that prevents unnecessary message duplication by processing each message only once, even if the message is received more than once.
The following diagram illustrates what happens when message deduplication is disabled vs. enabled:
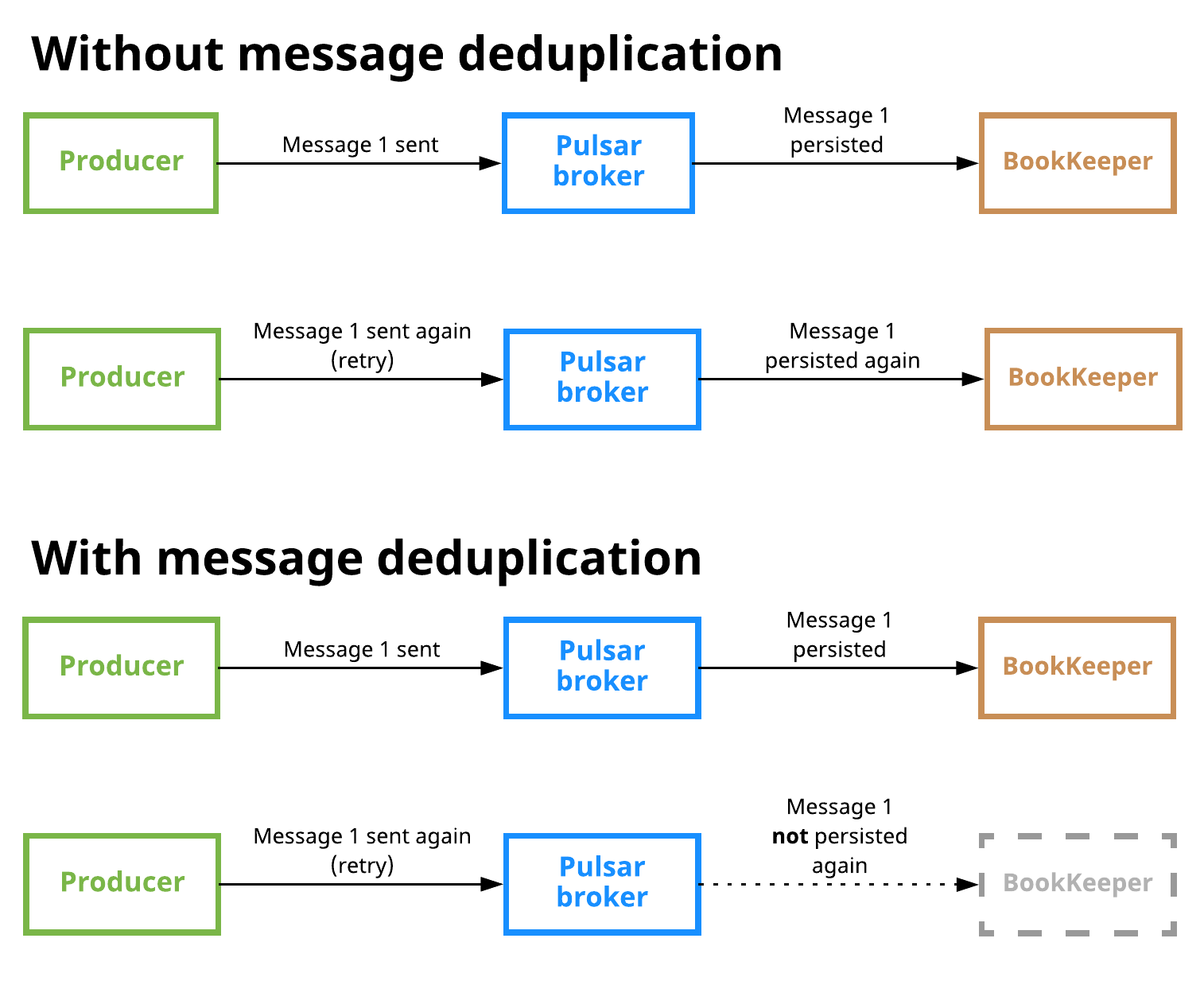
Message deduplication is disabled in the scenario shown at the top. Here, a producer publishes message 1 on a topic; the message reaches a Pulsar broker and is persisted to BookKeeper. The producer then sends message 1 again (in this case due to some retry logic), and the message is received by the broker and stored in BookKeeper again, which means that duplication has occurred.
In the second scenario at the bottom, the producer publishes message 1, which is received by the broker and persisted, as in the first scenario. When the producer attempts to publish the message again, however, the broker knows that it has already seen message 1 and thus does not persist the message.
Message deduplication is handled at the namespace level or the topic level. For more instructions, see the message deduplication cookbook.
Producer idempotency
The other available approach to message deduplication is to ensure that each message is only produced once. This approach is typically called producer idempotency. The drawback of this approach is that it defers the work of message deduplication to the application. In Pulsar, this is handled at the broker level, so you do not need to modify your Pulsar client code. Instead, you only need to make administrative changes. For details, see Managing message deduplication.
Deduplication and effectively-once semantics
Message deduplication makes Pulsar an ideal messaging system to be used in conjunction with stream processing engines (SPEs) and other systems seeking to provide effectively-once processing semantics. Messaging systems that do not offer automatic message deduplication require the SPE or other system to guarantee deduplication, which means that strict message ordering comes at the cost of burdening the application with the responsibility of deduplication. With Pulsar, strict ordering guarantees come at no application-level cost.
You can find more in-depth information in this post.
Delayed message delivery
Delayed message delivery enables you to consume a message later rather than immediately. In this mechanism, a message is stored in BookKeeper, DelayedDeliveryTracker maintains the time index(time -> messageId) in memory after published to a broker, and it is delivered to a consumer once the specific delayed time is passed.
Delayed message delivery only works in Shared subscription type. In Exclusive and Failover subscription types, the delayed message is dispatched immediately.
The diagram below illustrates the concept of delayed message delivery:
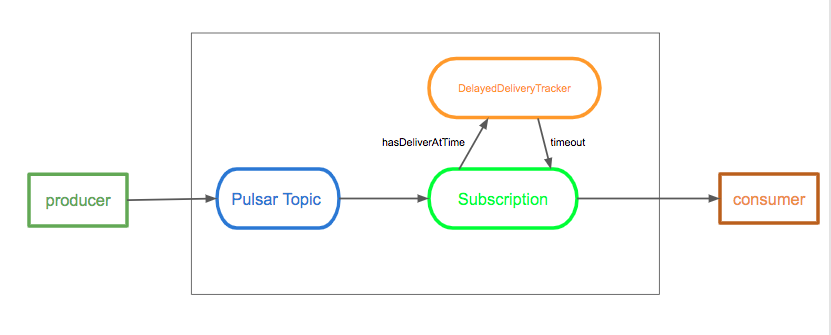
A broker saves a message without any check. When a consumer consumes a message, if the message is set to delay, then the message is added to DelayedDeliveryTracker. A subscription checks and gets timeout messages from DelayedDeliveryTracker.
Broker
Delayed message delivery is enabled by default. You can change it in the broker configuration file as below:
# Whether to enable the delayed delivery for messages.
# If disabled, messages are immediately delivered and there is no tracking overhead.
delayedDeliveryEnabled=true
# Control the ticking time for the retry of delayed message delivery,
# affecting the accuracy of the delivery time compared to the scheduled time.
# Default is 1 second.
delayedDeliveryTickTimeMillis=1000
Producer
The following is an example of delayed message delivery for a producer in Java:
// message to be delivered at the configured delay interval
producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();